We’re on post #4 of our OODA and endpoint triage series, and it’s time to talk about how to make data-based decisions during incident response.
I was reminded by the series this week at RSA when hearing orchestration companies talk about how many SOCs don’t know what their current incident response procedures are, and that is the first step before the process can be automated. OODA is one way to think about your process and what should be automated or not.
This post…
- …recaps where we are in the series
- …talks about the “Decision” phase (the “D” in OODA)
- …applies our approach to this phase to the original example case.
Series Recap
Let’s quickly recap where this post fits into the 5-part OODA series.
- The previous 9-part “Intro to IR” series focused on breaking up big digital investigation questions (IQs) into smaller investigative questions. It focused on topics like answering “Is there evidence malware persistence mechanisms?” or “Are there suspicious user accounts?”
- This OODA series is about making the numerous decisions that need to occur in that process
- OODA is a decision-making model that is natural to many people but also formalized to help optimize processes
- It consists of four phases that continue to repeat and provide feedback. The idea is to quickly iterate through them faster than your adversary and therefore make decisions faster than them and answer your IQs quickly.
What’s OODA Again?
OODA is an acronym with four repeating phases:
- Observe: Observe the situation using a variety of sources that are available. You will never be able to collect all data before making your first decision. In a previous post, we talked about endpoint and network visibility
- Orient: Use your experience and training to make sense of what you are seeing so that you can answer your IQs. Make hypotheses about the answers. This was the focus of the last post, and it talked about data overload, confidence values, and alternative hypotheses
- Decide: Based on your goals, orientation, and timing needs, decide on what action to take and when. Actions could include testing a hypothesis about the current state (i.e. get more data) or to try to change the predictions about what will happen next (i.e. thwart an intruder). We’ll talk about deciding in this post
- Act: Implement the decision.
The impact of the action (and at all stages) should be observed and fed back so that a new orientation can be made and another follow on decision and action.
Here is a graphic focused on endpoint triage with details that we’ve covered so far:
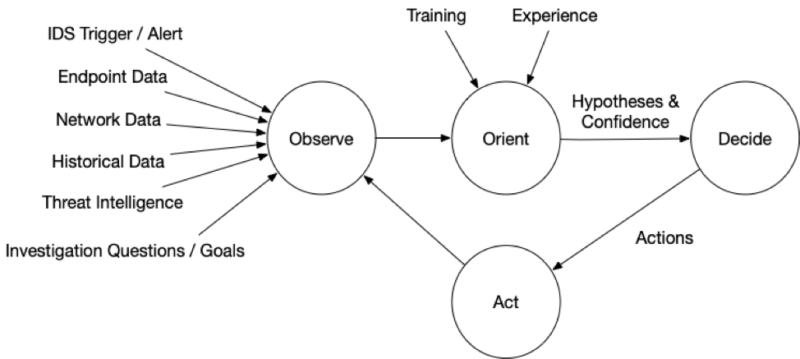
Making Incident Response Decisions
During endpoint triage, the goal of the “Decision” phase is to make an actionable decision that allows us to answer our investigative questions (IQ) so that we can act on it in the next phase (“Action”). The main task in this phase is to come up with possible actions and pick one.
There are three general steps to making decisions:
- Identify possible actions/next steps for each hypothesis
- Identify the risks and benefits of each action
- Pick actions based on the risk/benefits and the confidence of the hypothesis.
For example, we may have a hypothesis that a process is malware. If we have high confidence in that hypothesis, we may decide that there is nothing else to do (from a triage perspective), and we should move on to remediation. But, if our confidence is low (perhaps we are suspicious about it only because of its name), then we may decide to collect more information about it.
Levels of OODAs (Oodles of OODAs)
Before we dive into the decisions that can be made, it’s important to remember that the focus of this series is on making micro-level decisions about a single endpoint. Often times, there is a macro-level process that encompasses a bigger incident and perhaps the entire network.
We can think of levels of OODA loops that occur when decisions are made to start new investigations. I’m sure some would argue that there is only one OODA loop, but when working on teams with people working on different problems, I think it is easier to think about each person having their own OODA loop since they are making decisions on their own.
An Example of Making Decisions in Incident Response
Let’s say a security team is always trying to answer broad questions such as “has my network been compromised” or “has our data been compromised.” The team is constantly trying to answer those questions and is in their own OODA loop that observes and orients around daily activity and makes decisions.
At some point in that daily observation and orienting, they’ll decide to start an endpoint triage investigation if that endpoint is doing suspicious things. That is their “Action,” and it starts the endpoint triage OODA. When it is complete, they’ll be able to make other decisions given the knowledge of the current state of the network (which may have changed since the endpoint triage started).
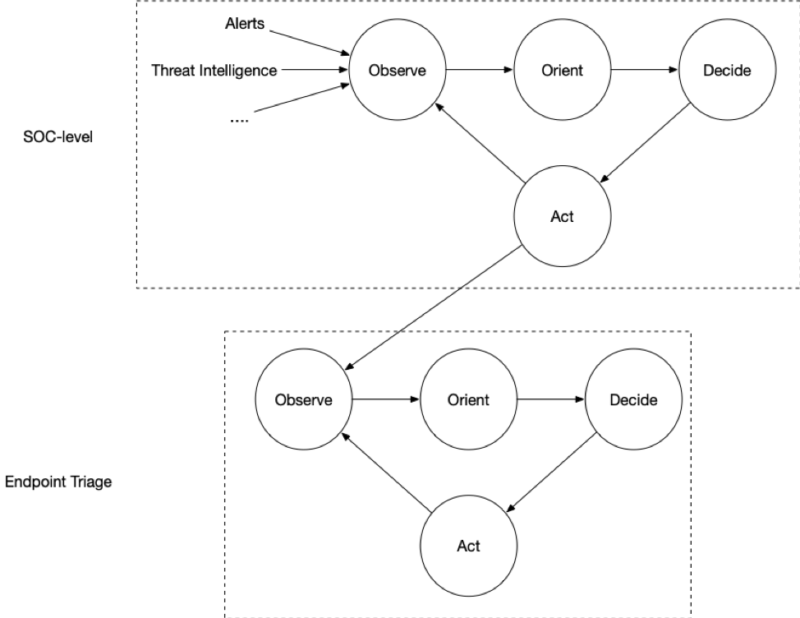
Keep this in mind in this post because it is easy to think of actions and decisions that are out of the scope of the current loop. Actions that are usually outside of endpoint triage scope include:
- Isolating the host to reduce further damage
- Remediation to kill processes, delete files, etc.
- Searching other systems to scope the incident.
These often require hypotheses about what the intruder is doing, what they are after, etc. that are better done at the higher-level. For example, instead of cleaning up an endpoint, the team may decide to monitor it to determine what other systems are involved.
Identifying Actions
The input to this phase is a list of hypotheses about what is going on and associated confidence values. We need to first come up with possible actions that we can do to either better understand or take control of the situation.
Often times, the types of actions are related to the confidence level.
High Confidence
If you have high confidence about your hypothesis, then maybe the triage is over or its time to move on to another question.
For example:
- Finished: If you have high confidence that you answered the original question (such “are there suspicious logins?”), then you are done and isolation and remediation will take place in the upper loop
- Next Question: If you previously broke up a bigger question into smaller questions and just confidently answered the smaller question, then the next action could be to focus on another small question. For example, move on to malware topics if no suspicious logins were found
- New Question: If you have high confidence that the data doesn’t exist to answer a question (such as “what process made a network connection”), then maybe you need to refine the question to something that can be answered, such as “are there any suspicious processes?”
If you decide to move on to a new question, then the corresponding action may involve data collection or searching.
Low Confidence
If you have low confidence about your hypothesis, then often the next step is to get more data from either additional searches (in the case of continuous monitoring) or getting data from the endpoint.
Knowing what additional types of data to get requires knowledge about how compromises work and what intruders do. The topics from the Intro to IR Series can help with this. If you are suspicious about a running process, you could always collect data on persistence mechanisms to see how it started or look at a timeline to see what happened before the process started.
Automation and Playbooks
It can be hard for some analysts and investigators to come up with all of the possible actions. This results in inconsistent results. This is what has motivated many organizations to use orchestration systems and develop playbooks for common tasks.
This was also one of the motivations for the Cyber Triage recommendation engine. When you mark an item as “Bad,” it will suggest other things that you may want to investigate (i.e. new actions).
Identify the Benefits and Risks of Actions and Decide
Like every decision in life, endpoint triage decisions require you to consider the pros/cons (i.e. benefits/risks) of each action that you are considering. But, there are few risks to endpoint triage actions except potentially alerting the intruder if you need to go back and poke around or taking more time.
The decisions that have the biggest risk are at the higher-level OODA that deal with isolation, remediation, observation, etc. because those can have a negative business impact.
Based on the potential upside and downsides, pick the action that you think is best.
Making Decisions During Incident Response: Picking Up on A Previous Example
We’ve been working on the same example throughout the series.
Let’s update them for the “Decision” step.
Suspicious Network Traffic
As a refresher, we saw suspicious network traffic from a laptop and wanted to answer “what process on the laptop made the connection?”
We used Cyber Triage to collect data from the endpoint about running active network connections but didn’t see any to the watering hole host. So, we can’t answer the question with the data in hand.
We had two hypotheses, both of which were low confidence given the data we had:
- The process that made the connection has since terminated
- The process is still running but has simply closed the connection.
There are several actions that we could take at this point:
| Possible Actions | Benefit | Risk |
| Collect memory, executables, and other files for running processes to see if they have unobfuscated references to the IP or hostname. | Would directly answer the question if the hostname was found. | It’s likely that the name is obfuscated and this search won’t find anything. |
| Analyze the running processes to look for any that could be malware. | Will find possible malware that could have made the connection. | Won’t find anything if the malware process exited or if it is unique malware. |
| Look for malware persistence by looking for startup items, scheduled tasks, and WMI actions. | Will find possible malware that could have made the connection, even if it was no longer running. | The process may have been manually started and therefore not found. May not find unique and never-seen-before malware. |
All three options have unique benefits and low risk, so we decide to do all three at the same time so that we can more quickly get some answers.
Compromise Assessment
The other example we’ve been tracking was a proactive compromise assessment on the executive’s computers. We used Cyber Triage to collect data about malware and user activity. We didn’t find malware traces, but there was a high amount of outbound remote desktop activity.
The result from “Orient” was a low-to-medium confidence hypothesis that the system could be used for lateral movement. But, we didn’t know enough about if the executive used a remote desktop.
There are several actions that we could take at this point:
| Possible Actions | Benefit | Risk |
| Talk to the executive to determine if they were her actions. | Provides the most direct answer to the hypothesis. | May not want to get the executive involved yet. |
| Research each host that was RDPed into to understand what they are used for. | May be able to determine if the executive would have any interest to log into them. | Probably not enough to fully prove or refute the hypothesis. |
| Examine each of the destinations to determine if they have suspicious data. | If there is lateral movement, those hosts may have other clues of malicious activity. | Takes the most time of the three options. |
Talking to the executive will provide the best data point, and then we decided to take that step first. If the connections were not from them, then some of the other actions will be useful (in addition to changing the executive’s password).
Conclusion
The hardest part of the “Decision” phase is often understanding what your possible actions are. This is one of the benefits of automating processes and playbooks so that you get a consistent result from different analysts.
If you need more endpoint visibility and help identifying the next possible actions, try out the evaluation version of Cyber Triage. It’s an agentless system that collects, analyzes, and correlates endpoint data.
If you liked this content and want to make sure you don’t miss our next article, sign up for the Cyber RespondIR email!