In the last post, we talked about our excitement for the new 3.0 release and its new database (which is the same one that Autopsy uses). One of the benefits of this new database is that we can take advantage of cloud-based database services. As we’ll see, the cloud can make it easier to access data in client networks, scale resources, and perform cloud forensics.
This is the first post in a series of three and we’re going to focus first on Amazon Web Services (AWS). We’ll start off talking about using the cloud and then we’ll dive into AWS specifics. Because Cyber Triage and Autopsy share the same database, the basic concepts outlined here also apply to Autopsy.
2025 Update: Since releasing this post and helping our customers, we now recommend that you always use a PostgreSQL database on the same VM as the Cyber Triage Server. We see many performance issues when using the cloud native databases.
What Is DFIR in the Cloud?
Combining the terms “DFIR” or “forensics” with “cloud” in various combinations (cloud forensics, forensics in the cloud, could-native forensics, etc.) means different things to different people. It gets confusing.
This series of articles is about running Cyber Triage in the cloud to analyze any kind of host data. The goal is to use cloud infrastructure, such as servers, databases, and storage instead of buying dedicated hardware.
You Might Also Like
Cyber Triage on Azure: DFIR in the Cloud
Cyber Triage on Google Cloud: DFIR in the Cloud
To be clear, this article is not about the collection or analysis of AWS-specific artifacts.
All versions of Cyber Triage store results in a database. The Standard version of Cyber Triage uses a local SQLite database and the Team version uses PostgreSQL.
When you are running Cyber Triage Team in a cloud, you’ll have at least two database options:
- Setting up a VM and installing PostgreSQL on it
- Using a cloud-specific database service
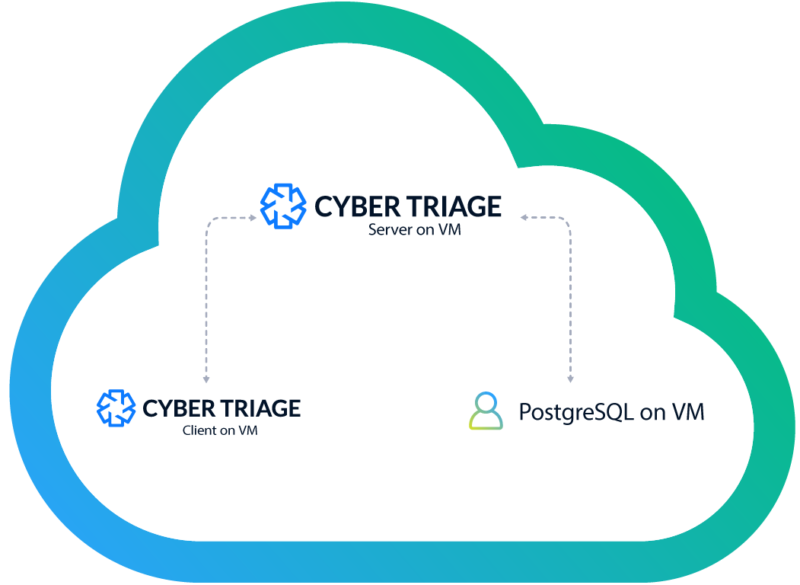
If you run PostgreSQL on a VM, your architecture will look like below. This essentially the same as running it on-premise with your own hardware. Configuration of this is already covered in the Cyber Triage User Manual.
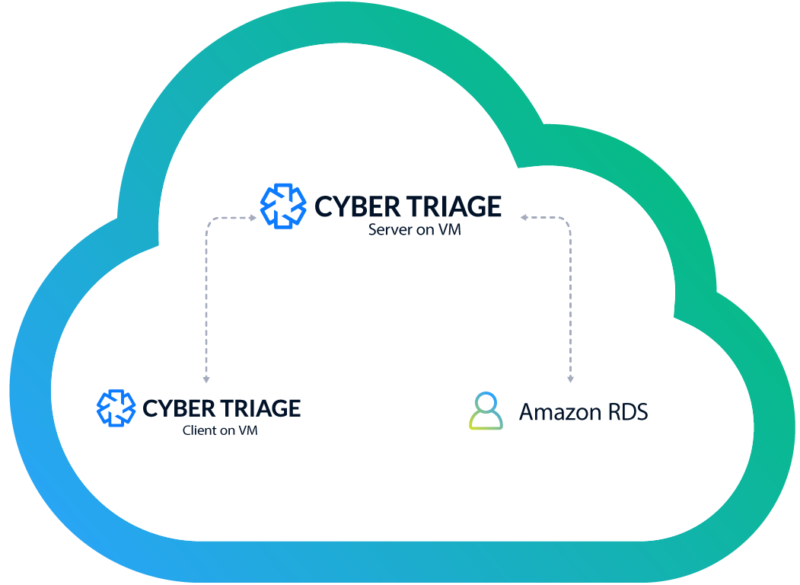
Instead of installing PostgeSQL on your own, you can use a cloud-provided service, for example AWS Relational Database Service (RDS). When you use one of these services, the cloud provider will take care of maintaining (and sometimes scaling of) the servers. The architecture is very similar, except that you are not launching a VM for the database.
If you are going to run Cyber Triage Team in the cloud, then we recommend that everything should be running in the cloud. That includes the clients. That’s what we’ve optimized for. It is possible to extend your VPC via VPN and have your clients in remote locations, but it will be slower. The Cyber Triage server should not be on a public IP.
Why Do Forensics in the Cloud?
There are a few main motivations our customers have for setting up their lab in the cloud:
- Scaling: It’s easier for them to set up Server VMs and expand storage as needed.
- Access: For consultants and MSSPs, a cloud is a central place that doesn’t require either party to give the other VPN access to their internal network. The cloud is also an easier place for responders to get access to when they are traveling or working remotely.
- Maintenance: If you use could-provided services, then you will likely not need to worry about updating the software and backups.
Here’s an example setup of using Cyber Triage in the cloud:
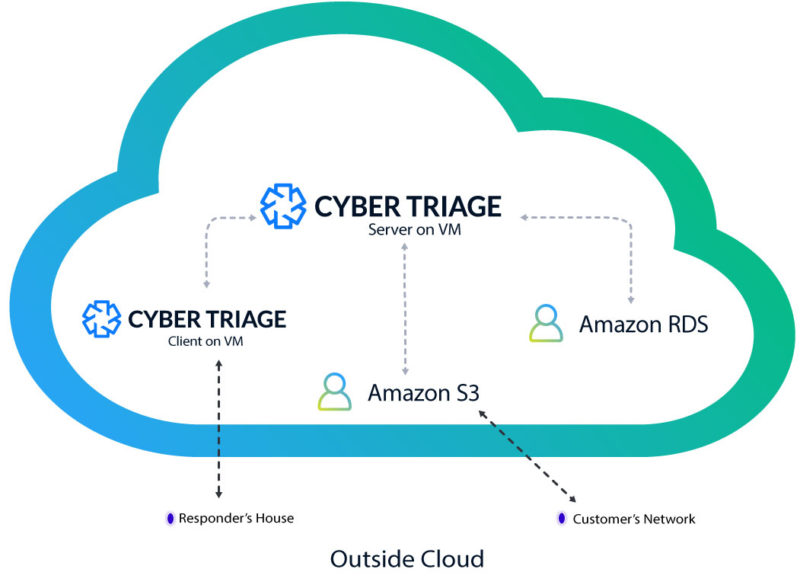
- A customer runs the Cyber Triage collection tool on a suspect host in their network and uploads the artifacts to an AWS S3 bucket (previous blog post).
- The responder logs in from home and imports the data into the Cyber Triage Server.
- Results are saved to the AWS database service.
- The Cyber Triage Server will analyze all of the artifacts and assign scores.
- Other examiners can login and assist as needed.
AWS Databases For Forensics
AWS is the most popular cloud provider and they have no shortage of managed database options. Their database page currently lists 11 database services. While this may seem overwhelming, only 2 are relevant for Cyber Triage and they are both in fact related under the covers.
The Relational Database Service (RDS) manages the database engine of your choosing. There are two relevant engines:
- PostgreSQL: AWS will manage a PostgreSQL server for you and deal with upgrades, fail over, etc.
- Aurora: Amazon wrote this database engine to take full advantage of the cloud. It uses PostgreSQL APIs, so Cyber Triage can easily communicate with it even though the underlying storage and scaling is different than a PostgreSQL server. Because Aurora is optimized for AWS, it is the least expensive service.
Aurora has two further options:
- Provisioned: You will have dedicated compute nodes to run your Aurora server. You will constantly pay while the servers are running.
- Serverless: AWS will bring compute nodes up and down as needed. You will pay only for when you are querying the database.
While the serverless Aurora sounds attractive for most groups, it had the worst performance with the Cyber Triage use cases.
And of course, we also need to consider that you don’t need an official database service and you can instead launch a VM instance and install PostgreSQL on it. This will be cheaper than using one of the managed services, but you will be responsible for updates and management.
Picking an AWS Database
We did some basic testing and cost profiling and will share them here. We performed two tests per configuration. One was to time how long it takes to ingest a single copy of a large test collection. The second was to time how long it takes to add 50 copies of that collection with three being processed in parallel. The collection contained 2.5GB of uncompressed JSON data.
Note that there are LOTS of AWS memory, CPU, and IO settings and we did not exhaustively try all of them. The goal here is to provide some basic direction on pros and cons of each. Maybe we’ll update this with better numbers if we do more tests.
Here are the 2021 results, ordered by processing time.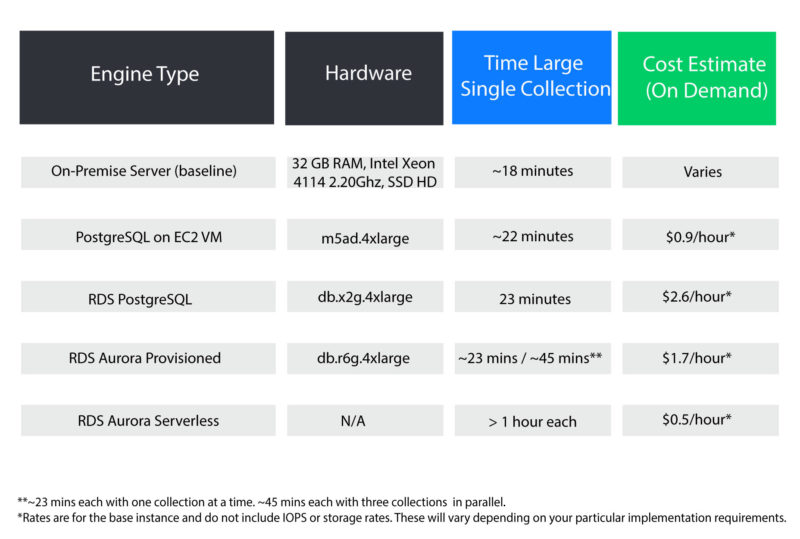
As can be seen, Aurora had the worst performance. To minimize its resource usage, Aurora slowly expands its resources as needed. Based on some blog posts and documentation, our theory is that Cyber Triage too quickly adds lots of data in big batches and the database needs to frequently block to continue expanding.
Our April 2025 recommendations are:
- Use PostgreSQL on the same VM as your Cyber Triage Server
- The cloud native databases are slower for the Cyber Triage usage patterns
How to Setup and Configure AWS
There are several steps to setting up AWS RDS and we don’t want to duplicate them and have them get out of date. So, we will instead give some quick pointers to the various services:
At the end of the process, you’ll get a URL to the database server.
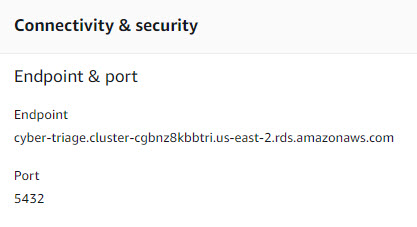
Simply copy and paste that URL into the PostgreSQL Database Settings panel along with the login and password that you used.
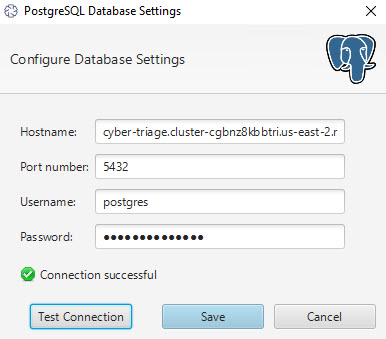
That’s it!
Conclusion
For some organizations, the cloud allows them to quickly expand resources and get easy access to data. But, as you can see from the numbers above, local setups are often faster. If you want to try Cyber Triage in either your cloud network or on your laptop, then fill out this form here.

You Might Also Like
Cyber Triage on Azure: DFIR in the Cloud
Cyber Triage on Google Cloud: DFIR in the Cloud